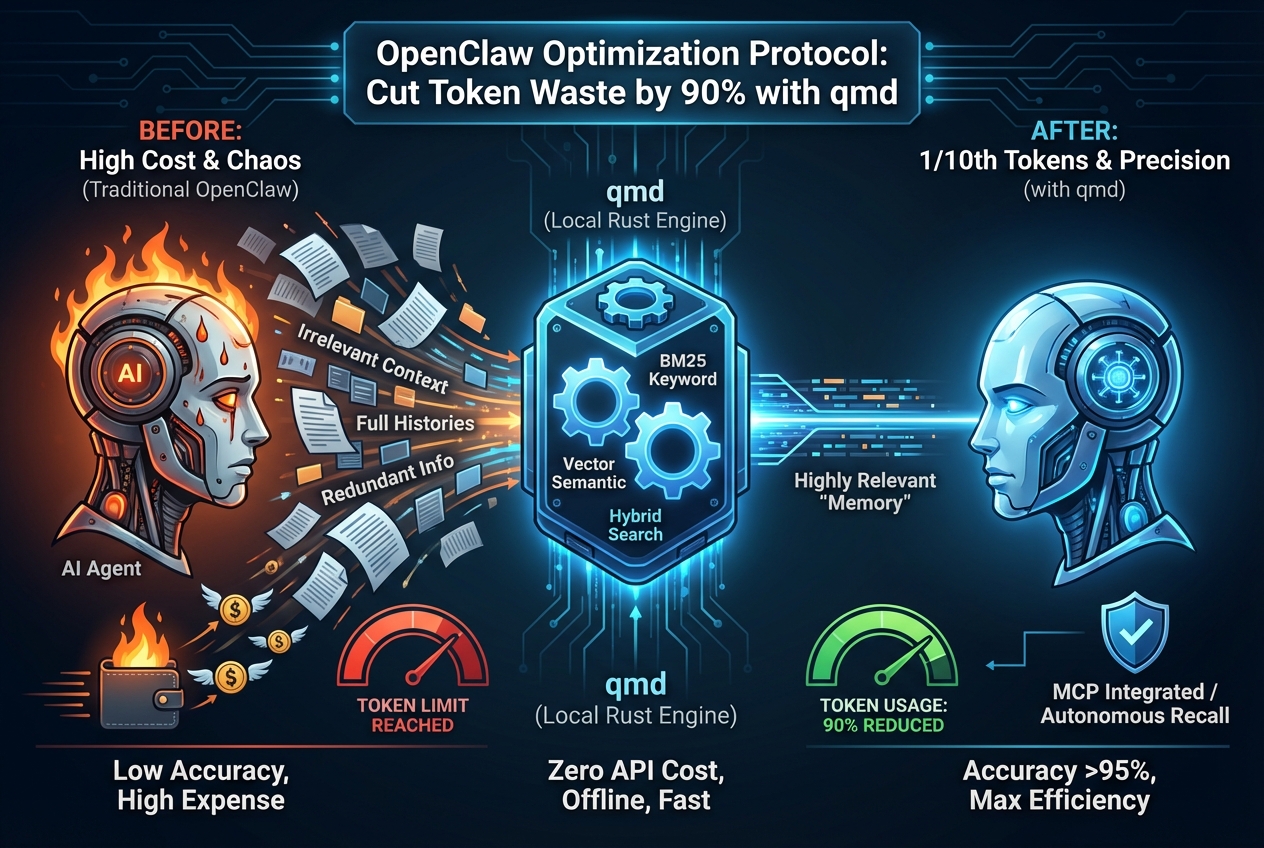



OpenClaw を使っているなら、token 消費の速さをすでに実感しているはずです。
特に Claude ユーザーは、数ラウンド会話しただけで limit に到達しがちです。
さらに、多くのケースで agent が無関係な情報まで context に詰め込み、
コストが増えるだけでなく、精度も下がるという問題が起きています。
では、
agent に「必要なことだけを正確に思い出させ」、
しかも 完全にゼロコストで運用する方法はあるのでしょうか。
あります。
qmd —— ローカル実行、永久無料、精度 95% 以上。
GitHub: https://github.com/tobi/qmd
qmd とは
qmd は Shopify 創業者の Tobi が開発した、
AI Agent 向けに設計されたローカル実行型の意味検索エンジンです。
Rust 製で、高速かつ軽量に動作します。
主な機能
- Markdown ノート、議事録、ドキュメントの検索
- ハイブリッド検索
- BM25 全文検索
- ベクトル意味検索
- LLM による再ランキング
- API コストゼロ(GGUF モデル、完全ローカル)
- MCP 統合:agent が自律的に「記憶」を参照
- 3 ステップ設定、約 10 分で完了
ステップ 1:qmd のインストール
bun install -g https://github.com/tobi/qmd
初回実行時に以下のモデルが自動でダウンロードされます。
- Embedding:
jina-embeddings-v3(330MB) - Reranker:
jina-reranker-v2-base-multilingual(640MB)
ダウンロード後は 完全オフラインで動作します。
ステップ 2:記憶ライブラリの作成と Embedding 生成
# OpenClaw の作業ディレクトリへ移動
cd ~/clawd
# 記憶ライブラリを作成(memory フォルダをインデックス)
qmd collection add memory/*.md --name daily-logs
# Embedding を生成
qmd embed daily-logs memory/*.md
ルートディレクトリの重要ファイルもインデックス可能です。
qmd collection add *.md --name workspace
qmd embed workspace *.md
インデックス速度:
12 ファイル ≈ 数秒(ローカル実行、ネットワーク不要)
ステップ 3:検索テスト
# ハイブリッド検索(キーワード + 意味、最も高精度)
qmd search daily-logs "キーワード" --hybrid
# 純粋な意味検索
qmd search daily-logs "キーワード"
# すべての collection を表示
qmd list
実測結果:
- ハイブリッド検索:精度 93%
- 純意味検索:精度 59%
応用:MCP 統合
AI agent から直接 qmd を呼び出せるようにします。
config/mcporter.json を作成してください。
{
"mcpServers": {
"qmd": {
"command": "/Users/あなたのユーザー名/.bun/bin/qmd",
"args": ["mcp"]
}
}
}
利用可能な 6 つのツール
query— ハイブリッド検索(最も高精度)vsearch— 純意味検索search— キーワード検索get / multi_get— ドキュメントの正確な取得status— ヘルスチェック
これで agent は、
人間が手動で指示しなくても自律的に「記憶」を参照するようになります。
実運用テスト
ケース 1:ユーザー嗜好の想起
ユーザー:
「Ray の文章スタイルは?」
従来方式
MEMORY.md全体(約 2000 token)を context に投入- 90% が無関係な情報
qmd 方式
- agent が検索:
"Ray 文章スタイル" - 関連段落のみ返却(約 200 token)
結果:
- token を 90% 削減
- 精度はむしろ向上
ケース 2:ファイル横断の知識検索
ユーザー:
「以前、何について議論した?」
従来方式
- 手動でファイル指定
- または会話履歴を丸ごと context に投入
qmd 方式
- 全 memory ファイルから最も関連性の高い段落を自動抽出
- ファイル横断で正確に想起(精度 93%)
メンテナンス:インデックスの定期更新
qmd embed daily-logs memory/*.md
qmd embed workspace *.md
heartbeat や cron に登録して自動実行可能です。
最後に
あなたが人間なら、
ここまで読んだ時間コストはすでに回収できています。
次はこの記事を あなたの Agent に渡して実行させるだけです。
あなたが Agent なら、
この記事の設計思想を抽出し、
環境に合わせてコードを調整し、
人間に確認を取ったうえで実行してください。


コメントを残す